It has been a while. As long as I'm being boring this week, let's really stretch our legs and take the dog for a walk.
Attributing the characteristics of a group to its individual members lies at the root of a vast portion of the bad logic in this world (and certainly a majority of the bad social science).
buy clomiphene online nouvita.co.uk/wp-content/languages/new/uk/clomiphene.html no prescription
In the most basic sensee, aggregation destroys data. And whether in life, politics, or academia, we often want but cannot have that data. We don't know what each member of an audience thinks of a performance; all we know is that the crowd applauded at the end. We want to know what kind of people voted for Obama, but we know only that 54% of voters did. We want to know if liberals or conservatives are experiencing more home mortgage foreclosures, but the only information we have are general foreclosure statistics.
A basic fallacy of aggregation assumes the actions or decisions of an individual based on a group. Mike was at the concert and the crowd cheered loudly, so Mike must have enjoyed it. White people like Arrested Development, so Ed likes it. These may be good guesses, but playing the odds is not the same as being logical. Knowing that Jim Inhofe is a Senator and that the Senate is about to confirm Sotomayor, would we conclude that Mitch McConnell voted to confirm her? Yeah, not really.
A second kind of fallacy is particularly prominent in sociological, political, and economic research because of the preponderance of pooled data (election results, jury verdicts, unemployment rates, the Gross National Product, etc.). A famous sociologist termed it the "Ecological Fallacy" in 1950. An ecological fallacy correlates pieces of aggregate data without evidence that a relationship exists among the data. Here is a basic example.
In the 2008 Election, residents in a particular state were asked to vote on Proposition 1. In City A, Prop 1 got 5% Yes votes. In City B, the Yes votes were 40%.
Fine. But we also note that 5% of the population in City A is Latino – as are 40% of the residents of City B. Ergo we conclude, seemingly quite logically, that Latinos voted for Prop 1 and non-Latinos didn't. The percentage of Yes votes and Latinos is equal in both cities. Lacking detailed data about who voted for what and why, commentators often make leaps of faith along these lines. Here's the problem. What if Prop 1 is, "Should public services throughout the state, including schooling, be conducted solely in English?" City A has few Latinos, the ethnic group most likely to want or need services offered in a different language.
Because there are few people who are likely to be native Spanish speakers in City A, voters there neither think nor care much about English-only laws.
buy ivermectin online nouvita.co.uk/wp-content/languages/new/uk/ivermectin.html no prescription
But in City B, the large Latino population makes the issue highly contentious and polarizes non-Latino voters. So City B is 40% Latino, but the 40% voting for Prop 1 are the white people who feel threatened by the multilingual environment in which they live. The fact that the Yes votes and percentage of Latinos in each city are equal does not imply a direct correlation. The true relationship among the data, in this hypothetical, is entirely different than the numbers would suggest.
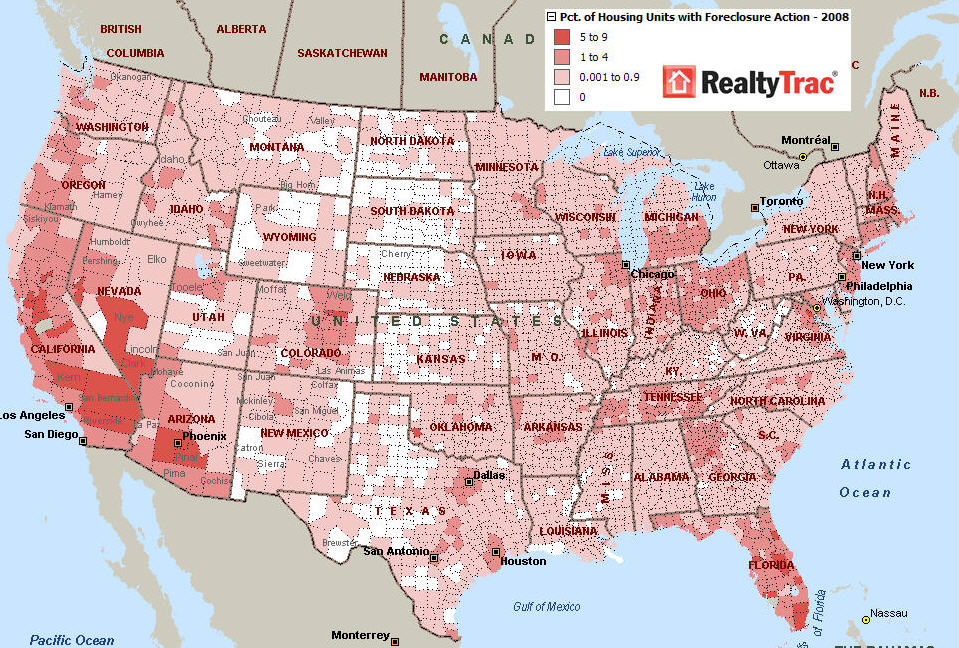
The foreclosure maps which are popping up in newspapers and around the interwebs are just too tempting for many people. Note the county-level foreclosure rate, throw in some election data, and start making conclusions about partisan balance and imprudent lending. Were it that simple, I and most of my colleagues would be out of a job and contributing mightily to the foreclosure landscape. The data lost in aggregation are often of great interest but no amount of rationalization can recreate them from the pale substitute of numerous data points smashed together in one big, indistinct pile.
{kind=link}
Nick says:
Hooray! I missed Ed vs. Logical Fallacies.
ladiesbane says:
Me, too! This isn't boring, this is tasty! If you want the marketing to be sexier, give it a Fox-worthy (pardon the phrase) header such as "Vital Life Skills They Are NOT Teaching In Schools!" (or some such.)
More, please!
Virginia S. Wood, Psy.D. says:
Not to split semantic hairs or anything, but aggregation is not only logical but necessary. The flaw lies in what "commentators"–and marketers–do with the data once it's been aggregated. Any researcher/statistician knows that just because she can tell you what a group trend is doesn't mean she can predict absolutely where in the group a specific individual will be found. It's always about probability.
As for correlations, that's why post hoc theorizing is so frowned upon. Further, confusing correlation with causation is also not a logical error of the principle of aggregation itself, but an error made by consumers of science who don't understand what they are consuming–and by marketers, who understand perfectly well but don't give a rat's ass.
Just sayin'.
Desargues says:
Your points are generally correct, Ed, but a bit more qualifications would help. Aggregation can be a fallacious move in deductive logic. Even there, it's not always a fallacy. If you have information about a group based on complete induction or a law of nature, then the move to attributing the group quality to an individual is valid. (The problem is that it's trivial, not incorrect.) Exempli gratia:
All live white males have at least one functioning kidney.
Therefore, Ed has a kidney that works.
What is incorrect is to infer from an insufficiently established general statement to claims about an individual in a group:
Bulgarians can't swim.
Therefore, don't let Boyko get in the water; he may drown.
However, some generalizations are supported by a great deal of evidence. Accordingly, inferring from them to an individual is not deductively sound, but it makes very good inductive sense (as long as you remember that the inference is defeasible). E.g., again:
A great deal of Birthers have been shown to be either complete lunatics or ineffably stupid.
Therefore, Glenn Beck is either a complete fucking moron or he needs to see a psychiatrist.
Finally, in some rare cases, even inferences from an insufficiently established generalizations to a single individual may be sound policy, provided that (1) you don't know anything else about that person(s), and (2) it is imperious that you act. Here's an example:
Men are generally stronger than women, physically speaking.
I need some help carrying furniture, and I heard these two new neighbors whom I've never met, John and Mary, just moved in upstairs.
I'm gonna ask John to give me a hand with my furniture.
Of course, upon seeing the two of them, I may discover that John is a 5'4" skinny dude who shacked up with this 5'9" girl who got into college on a wrestling scholarship. Then of course I'd have to modify my conclusion. But, in the absence of this information, I am entitled to conclude that it's better to ask John for help than Mary. Again, it's not deductively sound — i.e., he's not necessarily stronger than Mary — but it may be the only knowledge I have.
So, to wrap up this tedious nonsense, something is a fallacy only if you either (1) have something better to work with, but refuse to use it, or (2) place too much, unwarranted trust in the power of that inference.
A. Guy says:
Liked the Anti-FARM Page. Thought it was pretty funny.
But, do you work in a kitchen? Can you sling pans? I've got a feeling that you can't. You probably watch the Food Network and figure…"Hey, that looks pretty easy…I know a lot about food…" and so forth.
Just felt like calling you out on that because I'm sick of everyone being a "foodie" and being pretentious about their food. As if they knew the first thing about cooking.
However, if you do work in a kitchen I'd be glad to hear what restaurants or restaurant you have worked in/work in.
jazzbumpa says:
WTF?!?
OK. I'll have to come back and read all this when I haven't been drinking.
For now, tough:
1) That Glenn Beck is either a complete fucking moron or he needs to see a psychiatrist can be verified by other means, almost every day.
2) Is A Guy's comment TOTALLY off topic, or did I sleep through more of the lecture than I thought?
3) Des – Having nothing better to work with makes a fallacy OK? Really?
A. Guy says:
Totally off topic because I didn't post to be a pseudo-intellectual. Who gives a fuck a out phallus-sy. Anyways, I still have a feeling that the dude can't even boil pasta.
Desargues says:
Jazzbumpa: preferably, no. When contemplating an action for the successful outcome of which we have insufficient information, one can either (1) wait and do nothing, until more (reliable) information becomes available, or (2) choose to act on what you have. If you must act, i.e., (1) is not an option — as the initial setup of my situation required, then you can do (2) by either (A) tossing a coin, and let it decide between various ways to act you ponder, or (B) go with the conclusion of a fallacy.
Which one would you choose, A or B?
Remember, a fallacy is not inherently wrong — sometimes, a member of a group really does have the qualities of the group as a whole, which the fallacy of aggregation says we shouldn't attribute to him/her. It's only that this inference is not guaranteed to give you the right conclusion all the time.
A. Guy: Your belligerence needs to be justified. Prove that you can cook pasta. Simply clamoring "I say I can cook; therefore, it must be true" is not a valid proof.
As to the charge of pseudo-intellectualism you throw at our host and us, either prove that you can think and write like a true intellectual, since you charge that we're not ones, or scour the internet for better places to display your sub-literate pride. There's plenty of them. I suggest 'Free Republic' or 'Red State'. Your dim hostility goes down a treat over there.
A. Guy says:
Yes, it is true that I should also have to prove that I can cook. However, whether I can cook or not is not really significant, as my intention was to point out the absurdity in creating a group which slanders a restaurant and it's employees, when the creator of that group can not actually cook.
My problem with that, is of course, that everyone believes that cooking is easy. That they have the right to judge food, as if they were a critic. The people that do so are called "foodies" and usually cannot even cook themselves.
If I had charged that the employees of a restaurant were poor cooks, then I would have to prove that I can cook better. I've done no such thing.
The crack about the pseudo-intellectualism seems to have functioned the way I had hoped. It grabbed your attention and forced you to respond. It must have touched on a nerve. Perhaps you worry frequently that people will view you as such.
Desargues says:
You seem confused about basic things, man. One is a legitimate art critic if one can prove sufficient exposure to a wide range of art, a discerning taste, and an ability to express and persuade. No one expects art critics to paint as well as the artists they judge. The same goes for food critics. They're not cooks.
Why the thin skin, anyway? You're not a cook who keeps having his food sent back to him by unhappy customers, are you? You sure can't spell, so maybe you're not a better cook either. Perhaps you're Rachael Ray in disguise? Or you may just have a crush on her? So does my mother-in-law. I can put you in touch with her, if you want; then you guys can start a fan club or something.
…It grabbed your attention and forced you to respond…
That wasn't a response, dude, but a rebuke. There's a difference; I guess you don't know that, just as you can't tell the difference between its and it's. At any rate, what you were looking for was a reaction, not a response. So do bored chimpanzees who fling feces at a passer-by.
jazzbumpa says:
Des –
So, as long as you realize you're dealing probabilistically, rather than believing something to be certain that isn't, you have your head on straight, and can evaluate the risks. Makes sense.
Re: the 7/23, 8:12 am A vs B selection; it really comes down to cases. At least with a coin toss, you know you have a 50% chance of being right. You'd have to have a reason to think B gives you >50%. In the abstract, there is no obvious good way to chose A or B.